UIMA: busca por conceptos, no por palabras clave
09 de agosto, 2005 por Catuxa
IBM apuesta por la búsqueda basada en conceptos, en lugar de las tradicionales palabras clave, recuperar los datos en las redes corporativas.
El director de tecnologías de búsquedas de IBM Research, Arthur Ciccolo, resaltó la ausencia de investigación en este camino por parte de las grandes compañías de búsquedas en Internet, como Google, Yahoo y Microsoft se sigueen centradas en la Web pública, dejando a un lado la recuperación de información en la Intranets, y dado el volumen de datos que cada día generan, intercambian y almacenan las esmepresas, no debe ser, en absoluto, un tema para dejar en el olvido.
IBM, que recientemente presentó el proyecto de la nueva arquitectura de información de su Intranet, apostando por las folksonomías, pondrá a disposición del público Unstructured Information Management Architecture (UIMA), una tecnología que promete analizar textos, entre documentos y otros medios, para entender contenidos latentes, relaciones y hechos.
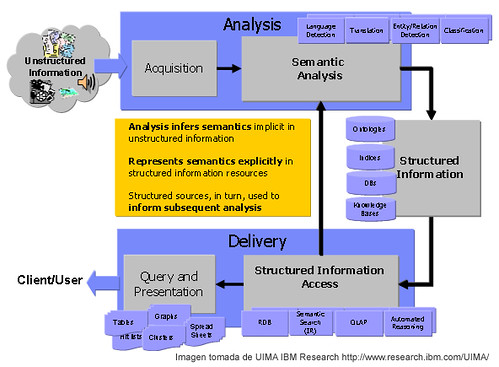
Según informan en El Navegante, IBM ya está ofreciendo su ‘software’ WebSphere OmniFind, que ayuda a los usuarios a realizar búsquedas de datos sin estructura en una variedad de formatos o lenguajes, ser localizados en bases de datos, archivos de correo electrónico, grabaciones de sonido, imágenes o video.
Los resultados que finalmente vean la luz y de los que podremos aprovecharnos, son parte de un trabajo de más de 4 años de IBM Search en colaboración con la Agencia de Proyectos de Búsqueda Avanzados de la Defensa de Estados Unidos.
Por el momento ya podemos descargarnos un kit de prueba y conocer un poco más del proyecto en IBMs alphaWorks Site.
- Nota de prensa desde IBM acerca de UIMA: IBM to Open Source Technology for Analysis of Unstructured Information













Comentarios recientes